

Благодаря имплементации нового метода использования памяти таблицы маршрутов, Express5 значительно расширил свои возможности в масштабировании маршрутов.
Express 5 — это новая интегральная схема специального назначения (Application-Specific Integrated Circuit, ASIC) компании Juniper Networks, разработанная специально для построения облачных сетей и нудж поставщиков услуг. Интегральная микросхема обеспечивает двукратную энергоэффективность, предоставляет расширенную информацию о трафике, аппаратную выборку, а также дополнительные функции и поддержку высокоскоростных и масштабируемых приложений маршрутизации, включая кластеры для обучения AI/ML с 16М маршрутов IPv4/IPv6 и 8М счетчиков с использованием устойчивой архитектуры на основе чиплетов.
Информационная база пересылки (Forwarding Information Base, FIB) — таблица в маршрутизаторе или коммутаторе, которая содержит информацию о том, куда направлять сетевой трафик для достижения его конечного назначения. FIB используется для принятия решений о пересылке пакетов на основе их IP-адресов.
Поддержка большой информационной базы пересылки (FIB) в ASIC требует поиска решения для балансировки работы между внутренней памятью Silicon и пропускной способностью внешней памяти. Интеграция всей FIB в чиплет физически невозможна для крупных FIB, а размещение всей FIB только во внешней памяти увеличивает стоимость проекта из-за необходимости выделения памяти для поиска маршрутов. Следовательно, в Express5 для решения этой задачи применяется комбинированный подход. Полная таблица маршрутов хранится во внешней основной памяти HBM, в то время как «рабочий» набор маршрутов содержится в достаточно большом внутреннем кэше. Процесс перемещения маршрутов из основной памяти в кэш полностью осуществляется аппаратно, без участия программного обеспечения. Таким образом, данный подход способен обеспечить как масштабируемость, так и хорошую производительность.
Сравнение масштабов FIB
Ниже приведено сравнение масштабов FIB, поддерживаемых различными версиями Express
| Чипсет | Поддерживаемые размеры ввода | Масштабирование FIB без сжатия | Масштабирование FIB с сжатием |
| Express1 и Express2 | 8, 16 слов | 4 миллиона записей по 8 слов | недоступно |
| Express3 | 5, 10 слов | 512 тыс. записей из 5 слов | недоступно |
| Express4 | 2, 5, 5, 10 слов | 2 миллиона записей по 2,5 слова | До 4 миллионов записей по 2,5 слова |
| Express5 | 2, 5, 5, 10 слов | 10 миллионов записей по 10 слов | До 16 миллионов записей по 10 слов |
Таблица 1: сравнение масштабов FIB
Более подробную информацию о принципах компрессии FIB можете прочитать в этом материале: https://community.juniper.net/blogs/nicolas-fevrier/2022/09/19/ptx-fib-compression.
Кэш FIB
| Процент от общего числа установленных маршрутов | Процент трафика, передаваемого по этим маршрутам |
| 0,50% | 90% |
| 4% | 9% |
| 23,50% | 0,90% |
| 72% | 0,10% |
Таблица 2: распределение FIB
Как отображено в таблице выше, чаще всего осуществляется доступ только к незначительной части FIB. Из этого следует, что если значительное количество активных маршрутов всегда находится в памяти оптимального размера с высокой пропускной способностью, то входной трафик может обрабатываться с максимальной пропускной способностью, даже если скорость чтения основной таблицы FIB ограничена.
В Express5 внутренняя разделяемая общая память служит в качестве кэша L1 для базы данных FIB, содержащей разделы для структур данных Nexthops и инкапсуляции. Специальное аппаратное устройство, ответственное за поиск маршрута, обрабатывает входной трафик, чтобы кэш был заполнен наиболее часто используемыми маршрутами.
При добавлении, удалении или изменении записей FIB в основной памяти через плоскость управления, кэш FIB сохраняет свою целосность.
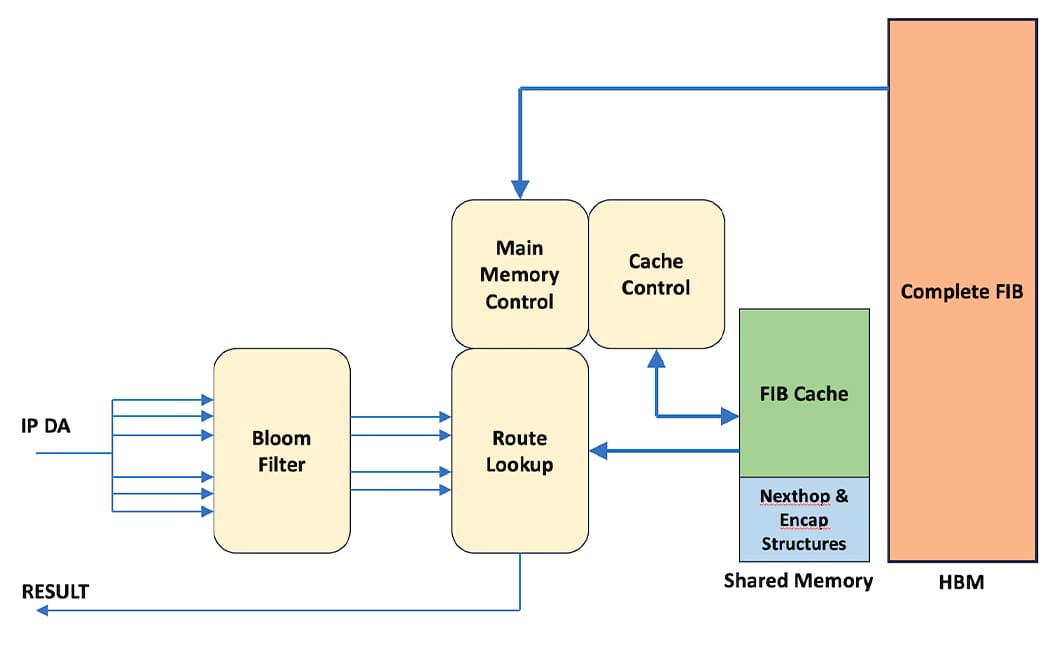
Рисунок 1: подсистема таблиц FIB
Для пересылки IP-адреса к его соответствующему адресу применяется набор масок префиксов, основанных на результатах фильтра Блума, которые затем проверяются в FIB. Этот процесс включает последовательную проверку кэша на совпадение с различными длинами префиксов, при которой выбирается наиболее подходящее совпадение. В случае отсутствия записи в кэше данные извлекаются из основной памяти и обновляются в кэше.
Размер кэша FIB можно программировать для размещения до 1 миллиона маршрутов. Если в любой момент времени количество активных маршрутов остается в этом диапазоне, то кэш способен обрабатывать входящий трафик с высокой эффективностью, соответствуя целям производительности, а также обеспечивая значительное масштабирование.
